Attention機構
はじめに
- Encoder-Decoder構造のSeq2seqモデルに対して追加された、Attention機構は後の機械学習モデルに大きな影響を与えている
- 主に自然言語処理/機械翻訳のモデルに注目して情報をまとめた
- Transformerは現行の人間の思考モデルと異なるプロセスであり直観的理解が難しいと考え、本記事では深く考えない
Attention機構が必要だった経緯
- 自然言語処理の分野で、Encoder-Decoder構造のモデルが機械翻訳の精度が向上したが、問題点を抱えていた
- 最大の問題点は、Encoderが出力する状態(翻訳前の文章情報を圧縮したもの)が固定長ベクトルのため、翻訳したい文章が長文になると精度が落ちる
- そこで、Decoderに与える情報として、Encoderが出力する状態に加えて、Decoderが出力する各単語が翻訳前のどの単語に対応するか(翻訳前のどの単語に注目してDecoderが出力する単語を決定すればよいか)に関する情報を与えることで、機械翻訳の精度を上げようとした
構造と機能詳細
- Attention機構は、Query, Key, Valueと呼ばれる要素を入力とし、後段のプロセスが注目すべき情報を出力する
Query, Key, Valueについて
- Query: $\bf{Q}$ $=$ $\bf{q}$
- 個人的にしっくりくる日訳:問いかけ
- 探している情報
- 例えば、訳したい単語の特徴ベクトル(Embedding)
- Rank: 1(1×$k$)
- Key: $\bf{K}$ $= ($ $\bf{k_1, k_2, …, k_m}$ $)$
- 個人的にしっくりくる日訳:識別子
- Valueのリファレンス情報
- 例えば、ある単語の特徴ベクトル(Embedding)
- Rank: 2($m$×$k$)
- Value: $\bf{V}$ $= ($ $\bf{v_1, v_2, …, v_m}$ $)$
- 個人的にしっくりくる日訳:値
- Keyが表す情報
- 例えば、ある単語自体のベクトル
- 同じ特徴ベクトルでも単語自体のベクトルが異なる場合がある(犬とdogなど)
- Rank: 2($m$×$k$)
処理のおおよその流れ
https://d2l.ai/chapter_attention-mechanisms-and-transformers/queries-keys-values.html

https://deeplearning.cs.cmu.edu/S23/document/slides/lec18.attention.pdf
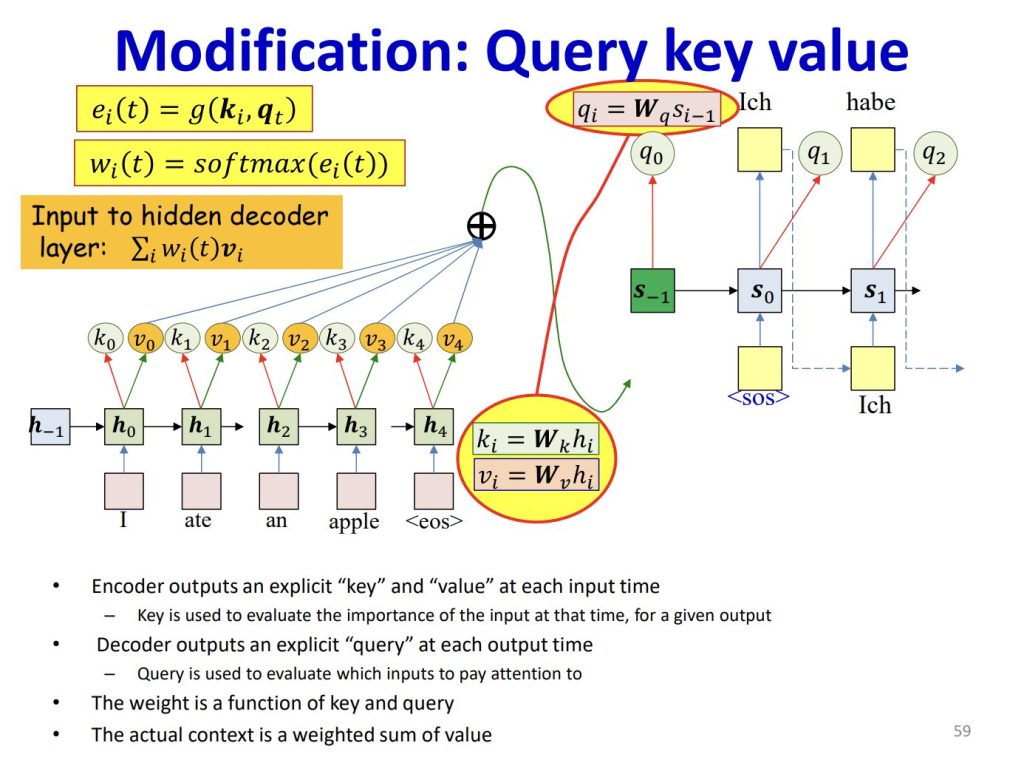
- Query, Key, Valueを算出
- 何らかの入力からQuery, Key, Valueに対応するベクトル$Q$, $K$, $V$を生成する
- 例:Encoder-Decoderを用いた言語翻訳の場合
- 翻訳したい文章をEncodingしたベクトル(Contextベクトル)から$K$, $V$を生成し、Decoderが出力するベクトルから$Q$を生成する
- $Q$, $K$, $V$を生成する際、元のデータからニューラルネットワークで生成することが多い
- Alignmentスコアを算出
- $Q$, $K$を用いて、Alignmentスコアと呼ばれる$q$と$k_n$($0<n<m$)の類似性を示すベクトルを生成する
- AlignmentスコアはAttentionスコア、Attention weight、Attention Mapなどとも呼ばれる。
- Alignmentスコアを算出する関数はAlignment score functionとも呼ばれる。

- AlignmentスコアからAttention層の出力を計算
- Alignmentスコアが$V$から注目すべき情報を抽出するマスクのような役割となり、後のプロセスが必要な情報を強調して渡すことができる
Attention機構の種類
Attention機構は視点によりいくつかの種類に分類される。数種類の組み合わせたAttention機構も可能である。
Global Attention / Local Attention
https://angelina-yang.medium.com/what-is-global-attention-in-deep-learning-53bd4525a389
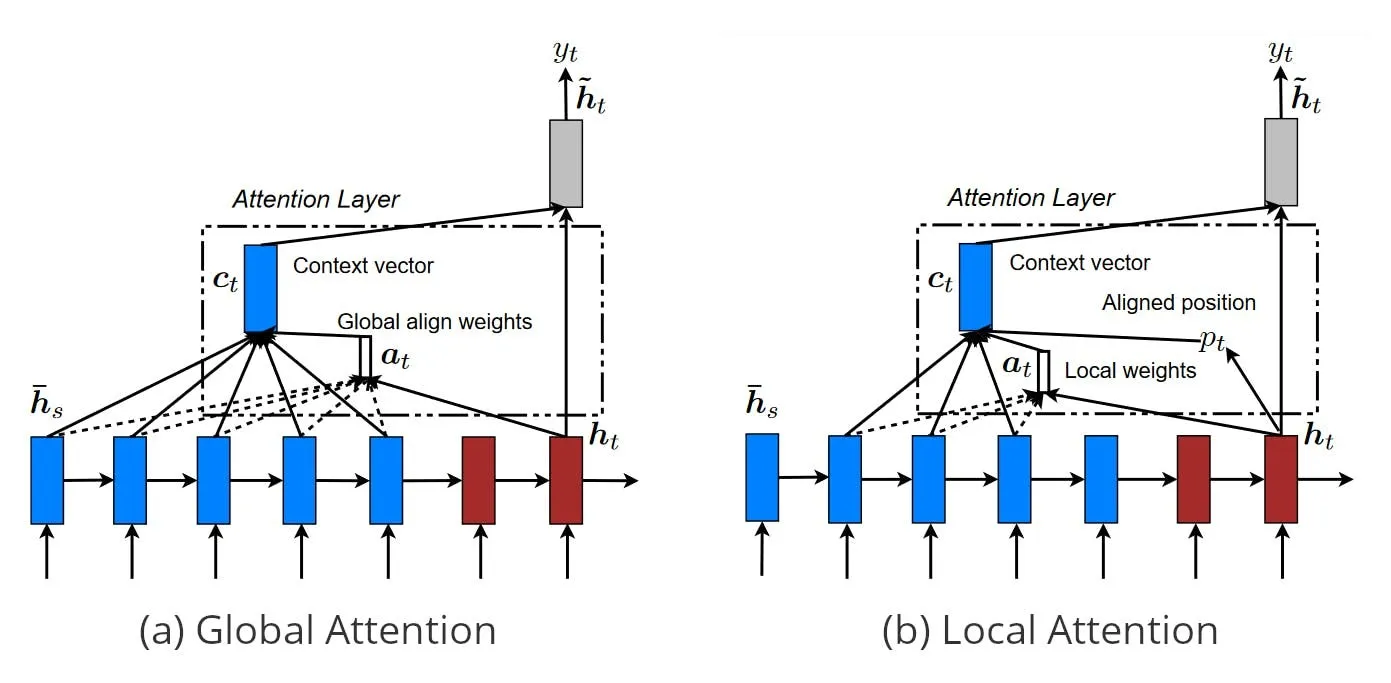
- Global Attention
- 全ての入力を考慮に入れることができる
- 入力のサイズが大きいと計算量が増加する
- Key, Valueにすべての入力を使うパターン
- Local Attention
- 入力の一部の考慮に入れる
- 計算コストが低い
- 微分不可能な演算が発生する
- Key, Valueに一部の入力を使うパターン
Hard Attention / Soft Attention
https://www.researchgate.net/publication/347344899_The_Latest_Trends_in_Attention_Mechanisms_and_Their_Application_in_Medical_Imaging

- Hard Attention
- Alignmentスコアの値が0か1
- Keyを選択することになる
- 微分不可能
- 強化学習的な探索が必要
- Soft Attention
- Alignmentスコアの値が0~1
- Keyに重みを付ける
- 微分可能
Self Attention / Cross Attention
https://medium.com/@geetkal67/attention-networks-a-simple-way-to-understand-cross-attention-3b396266d82e
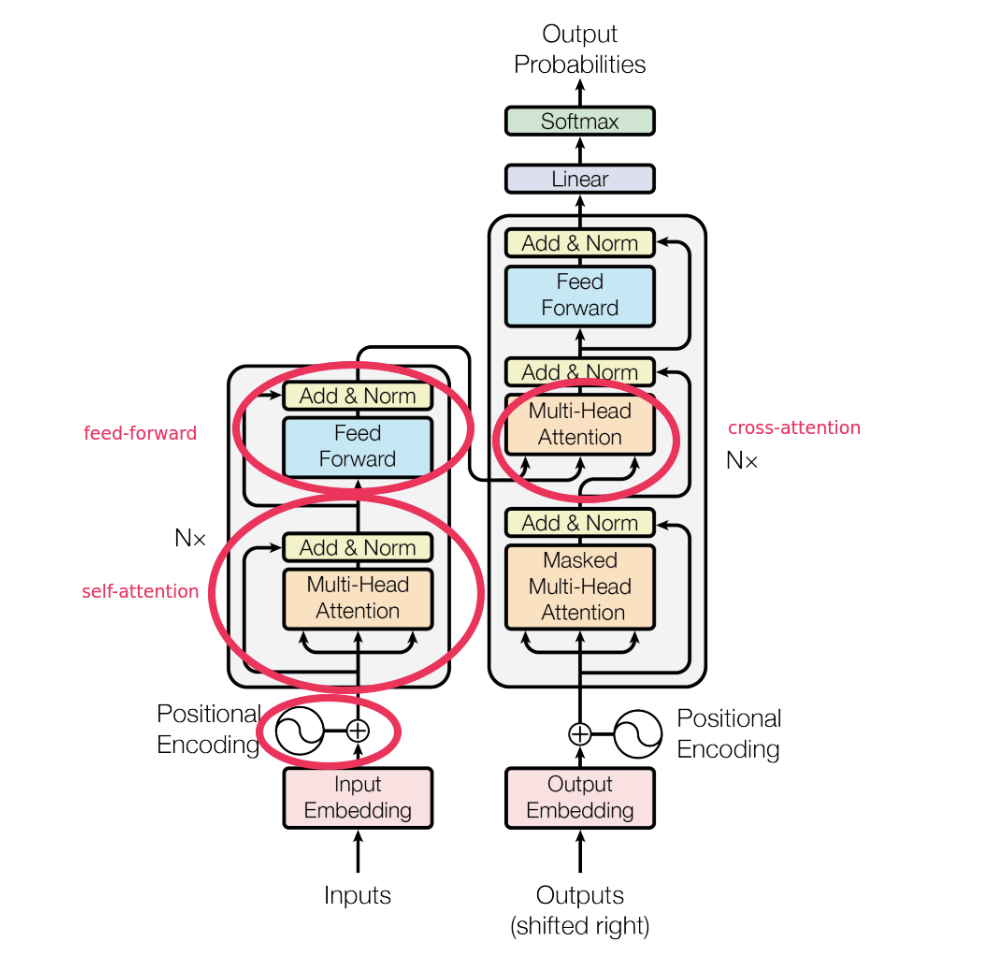
- Self Attention
- Query, Key, Valueを生成する元のデータが同じであるAttention機構
- intra-attention とも呼ばれる
- 特にmachine reading, abstractive summarization, image description generationに有用
- Cross Attention
- Queryを生成する元のデータとKey, Valueを生成する元のデータが異なるAttention機構
Single-head Attention / Multi-head Attention
調査中
参考
- https://www.youtube.com/watch?v=UPtG_38Oq8o
- https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- https://stats.stackexchange.com/questions/421935/what-exactly-are-keys-queries-and-values-in-attention-mechanisms
- https://jalammar.github.io/illustrated-gpt2/
- https://lilianweng.github.io/posts/2018-06-24-attention/
- https://machinelearningmastery.com/global-attention-for-encoder-decoder-recurrent-neural-networks/
- https://www.leewayhertz.com/attention-mechanism/
- https://www.linkedin.com/pulse/unpacking-query-key-value-transformers-analogy-database-mohamed-nabil/
- https://dmol.pub/dl/attention.html
- https://deeplearning.cs.cmu.edu/S23/document/slides/lec18.attention.pdf
- https://tasakawa.lolipop.jp/aidl/attention/page1.html