Encoder-Decoder構造
はじめに
- Seq2seqで有名になった機械学習のEncoder-Decoderモデルについて、定性的な理解をするための情報をまとめた
構造と機能
https://6chaoran.wordpress.com/2019/01/15/build-a-machine-translator-using-keras-part-1-seq2seq-with-lstm/
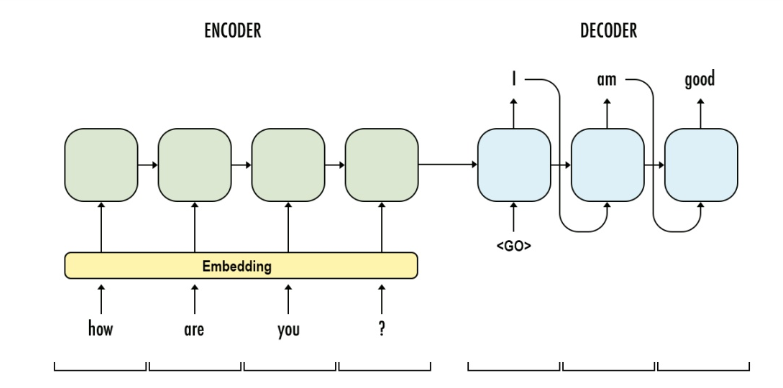
- Encoder
- 翻訳したい文字列を単語(厳密にはトークン)に分け、それぞれを意味に応じた数値化処理(Embedding)を施す
- 機械翻訳をする際、1まとまりとして扱う単位をトークンとしており、文章をトークンに分けるプログラムをtokenizerと呼ぶ
- 1単語目と初期状態をRNN(LSTM、GRU等)に入力、2単語目と前段のRNNの出力をRNNに入力、…と順にRNNで処理させることで、文脈(単語の順番)に関する情報を持たせた状態をEncoderの出力として得ることができる
- 状態を持つことができるRNNでなくCNN等のFeedforwardなニューラルネットワークの場合、時系列情報(単語の順番)に関する情報を持たせにくい
- LSTMはLong Short Term Memoryの略で、記憶ゲートと忘却ゲートをもたせたRNN
- GRUはGated Recurrent Unitの略で、LSTMと同様の機能を計算量を落として可能にしたRNN
- 文脈に関する情報について、前の単語だけでなく後の単語の情報も有用であるため、Encoderには双方向のRNNを利用することが有用とされている
- 翻訳したい文字列を単語(厳密にはトークン)に分け、それぞれを意味に応じた数値化処理(Embedding)を施す
- Decoder
- Encoderの出力状態と文頭を示すトークン(図で言うと<GO>、他のトークンの場合もある)をRNNに入力、1段目のRNNの出力状態と1段目のRNNの出力トークンをRNNに入力、…と順にRNNで処理させることで、文脈の情報を紐解き、翻訳後の文章(target)を出力する